無い物は作れ Tukubai流コマンド自作文化 : 第2章 sm2コマンドという道具の発明
道具になることを目指して作られたOpen usp Tukubai。それを構成している49のコマンド群。実際これらはどのようにして生まれたのだろうか。そのうちの1つで、表の合計値を求めるsm2コマンドの生い立ちを紹介する。
sm2コマンドとは
Open usp Tukubaiのsmで始まるコマンドは、sum-upという表計算の分野で頻出する操作を行うコマンドシリーズになっている。sm2の場合、たとえば次のように生徒の各教科のテスト成績表があると、これに基づいて生徒毎の合計を求めるといった用途に使われる。
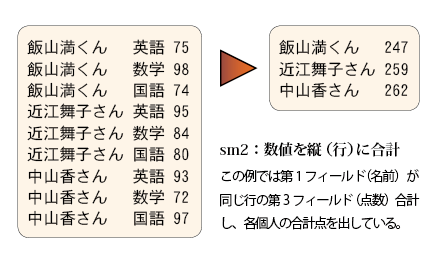
このsm2コマンドの誕生から仕様策定、機能の絞り込みや高速化などの開発過程を紹介する。
未来の開発者を想像する
頻出の操作であるなら迷うことなく作ればよい。しかし、まずはじめに、道具として本当に必要なものであるかどうかを検討する必要がある。既存コマンドをちょっと工夫して使えば済むのではないか考える必要がある。
あれば便利だろうと言ってコマンドを乱立させても、数が多いと覚えきれない。結果として、存在意義の薄いもの、使用頻度の低いものからどんどん使われなくなっていく。
ユニバーサル・シェル・プログラミング研究所にも、忘れ去られて今やハードディスクの肥やしとなっているコマンドが数千個ある。そうなってしまう未来が思い浮かぶなら、作らない方がよい。

「そのコマンドは本当に必要なのか」 ー ユニバーサル・シェル・プログラミング研究所では毎週、エンジニアたちが未来に求められるコマンドについて語り合う「コマンド研究会」と呼ばれる会議が開かれている。
作業指示の言葉をよく観察する
作るからには末永く使われるものでなければならない。だから使いやすい仕様を心がける。Tukubaiコマンドの場合、書式が作業指示をそのまま表現しているかどうかが重要になる。sm2を例にとって説明する。
sm2を作りはじめる前、表計算を行っていた作業現場では次のような会話がよくなされていた。
その表の1列目から2列目をキーにして3列目から6列目の合計を出しておいて
sm2はこれを実施するコマンドなのだが、この文章がそのままsm2の書式になっている。
sm2 [+count] <k1> <k2> <s1> <s2> <file>
先ほどの会話をこの書式に当てると次のようになる。
sm2 1 2 3 6 その表
オプションの+countを除けば、「合計を出す」という動詞がコマンド名に、他の名詞が引数に当てはまっている。このように現場でよく行われる会話を表現したものになっていれば、覚えやすいし、忘れる可能性も少なく、道具として認知される存在になりやすい。
単純でも頻繁に飛び交う動詞なら作る
現場の会話における動詞がコマンド名になっている、という点に特に注目してもらいたい。
sm2の話から少し逸れるが、逆に既存のコマンドのごく簡単な応用で実現できることであっても、あえてコマンド化した方がよい場合がある。それは、作業指示として頻繁に耳にする動詞だ。
たとえばOpen usp Tukubaiにはgyoというコマンドがある。これは単にテキストの行数を求めるだけのコマンドであり、wc -l | awk '{print $1}'とかawk 'END{print NR}'などとやれば簡単に求められる。それでもコマンド、つまり道具として成立したのは、「行数求めて」という指示(動詞)が現場で頻繁に飛び交っていること、そしてgyoコマンドの仕様がピタリとその指示を表現できることに理由がある。
言葉の観察がとても大切だ。また、専用のコマンドとして実装することで処理速度の高速化を実現できるという利点もある。行数を数えるだけの機能しかもたないgyoコマンドは、usp Tukubaiのエンタープライズ版ではきわめて高速化されており、wc(1)やawk(1)で同様のことをするよりも高速に処理を完了することができる。
オプションの扱い
sm2には1つだけオプションがある。これは各々の合計を出すのに使った元の行が何行あったのかを併記するためのものだ。最初の成績表の場合、各生徒の受けた科目は3つだったので3という数字を返す。後続のコマンドで平均点を求めたいという場合に有効だ。
しかしTukubaiの作法では、どうしても必要であるという場合を除いて、原則としてオプションはつけない。オプションもコマンド同様、乱立させても覚えきれずに忘れるからだ。
たとえば、頻用するls(1)コマンドの-rオプションの動作を知っているだろうか。ファイルの表示順が通常なら文字コード昇順であるところを降順にするものだ。しかし、文字コード順ではなくて大文字小文字を区別しない(辞書的な)降順にしたければ、結局sort(1)コマンドを併用することになる。結果、-rは使われることがなくなり、sort(1)コマンドを使えばよい、ということになる。
オプションもまた、付けるべきか付けざるべきか、あるいは、増やすぐらいなら別コマンドにすべきか、よく検討する必要がある。新機能が求められた時、新規コマンドで対応するか、追加オプションで対応するか、ちゃんと検討する必要がある。
機能を追加しない場合も説明しておこう。sm2では、たとえば「3番目から5番目、それから7番目の合計を出して」というように、k1〜k2やs1〜s2が不連続な指示が与えられた場合、対処できない。処理できるように改善が検討されているかといえば、その予定はない。
この判断も現場で行われる会話に基づいている。このような会話がされることがほとんどないというのが、そうした指定をできるようにはしないという判断の根拠になっている。稀なケースのために書式を複雑にしたら、sm2のソースコードはそれだけ複雑になり、パース処理の分だけ処理は遅くなる。そんな指示が来るなら、selfコマンドと組み合わせ、列が連続するようにあらかじめ入れ替える方がよい。このように、コマンドに持たせる機能のさじ加減を見極める上で、開発現場での会話に注目することが重要になる。
はじめはスクリプト系言語で実装してみる
エンタープライズシステム開発で使われるusp TukubaiのコマンドのほとんどはC言語で実装されているが、最初はどれもawk(1)やシェルスクリプトで作られた。定番の道具になるかわからず、廃れたり、試行錯誤によって仕様が変わる可能性を考えると、最初はスクリプト系言語で開発しておいた方がよい。
sm2も当初はawk(1)で実装されていた。当初の実装はもはや残っていないが、+countオプションをサポートしないごく簡易的なものならリスト1のようにすぐに作成できる。
リスト1. 当時のsm2をAWKで復元してみたもの
#!/usr/bin/awk -f
BEGIN {
if (ARGC < 4)
exit 1
k1=ARGV[1]
k2=ARGV[2]
s1=ARGV[3]
s2=ARGV[4]
if (k1 k2 s1 s2 ~ /[^0-9]/)
exit 1
if ((k1 > k2) || (s1 > s2))
exit 1
if ((k1 < 1) || (s1 < 1))
exit 1
file = (ARGV[5] != "") ? ARGV[5] : "-"
value[0]=0
delete value[0]
if (getline < file) {
key_old = $k1
for (i=k1+1; i<=k2; i++)
key_old = key_old " " $i
for (i=s1; i<=s2; i++)
value[i] += $i
while (getline < file) {
key = $k1
for (i=k1+1; i<=k2; i++)
key = key " " $i
if (key != key_old) {
print_total()
for (i in value)
delete value[i]
}
for (i=s1; i<=s2; i++)
value[i] += $i
key_old = key
}
}
print_total()
}
function print_total() {
printf("%s",key_old)
for (i=s1; i<=s2; i++)
printf(" %d"、value[i])
print ""
}
sum-upという操作は表計算では頻出するため、実際にsm2は多用され、重宝される道具になっている。しかし、前述したように50行程で書けてしまう。
すべてがそうとは限らないが、道具は概してこのように単純な構造をしている。もし何千行や何万行にも及ぶようなものができてしまったら、それは単機能なものになっておらず、道具として洗練されていないのかもしれない。
C言語への移植は、本当に必要とされてから
その後、sm2コマンドはC言語へと移植された。次第に道具としての必要性が認知され、不可欠な存在となって、このコマンドに対してスピードが求められるようになったからだ。C言語に移植した後は、C言語のエキスパートによって高速化のための改良が続けられている。高速化の作業に専念する為にも、スクリプト言語版で仕様をきっちり固めておくべきだ。
ソースファイルは大抵1つ
sm2のC言語版ソースファイルは掲載できないが、ソースファイルはsm2.cの1つだけである。これはTukubaiコマンドのほとんどにいえることだ。同規模のUnix標準コマンドも1つのファイルで構成されていることが多い。
こんなあきれるほど簡単なコマンドやシェルスクリプトによって、一部の大手企業の業務データが管理されていると聞かされたら唖然するだろう。しかし、優れた「道具」とは、そんなことをも可能にする。
USP MAGAZINE 2013 winter「【特集】無いものは作れ Tukubai流コマンド自作文化」より加筆修正後転載
※ usp Tukubaiはユニバーサル・シェル・プログラミング研究所の登録商標。
