UECジャーナル
ユニケージエンジニアの作法その四 変数ではなくファイルを活用せよ
ユニケージ開発手法では入力から出力へいたるデータの流れをなるべく一本化することで、設計・開発・実装・デバッグ・保守・改良などの作業の見通しをしやすくすることを心がけている。これを実現するひとつの方法が、安易に変数を増やさないことにある。

データの流れは一本化されている方がよい
変数は一時的なデータ記憶場所として便利だが、変数を多用すればするほどデータの流れという点において分岐が起こることになる。データは一本化され、その流れはひとつである方が好ましい。ユニケージ開発手法ではこれを実現する方法として、変数の使用を極力避け、かわりにファイルおよびパイプを使う方法を採用している。
次に、ユニケージエンジニアが実際に現場でコーディングしたスクリプトを取り上げ、変数ではなくファイルを活用する方法を示す。
変数を使ったスクリプト
#!/bin/sh
# ===== オプション取り込み =======================
CGI=$([ -n ${CONTENT_LENGTH} ] && \
dd bs=${CONTENT_LENGTH} | cgi-name -i_ -d_)
err=$?; [ $err != 0 ] && exit $err
# ===== 必要条件の抽出し、各変数へ代入 ===========
KAISHA_CD=$(echo "$CGI" | nameread KAISHA_CD)
err=$?; [ $err != 0 ] && exit $err
HINBAN=$(echo "$CGI" | nameread HINBAN)
err=$?; [ $err != 0 ] && exit $err
DAY_ST=$(echo "$CGI" | nameread DAY_ST)
err=$?; [ $err != 0 ] && exit $err
DAY_ED=$(echo "$CGI" | nameread DAY_ED)
err=$?; [ $err != 0 ] && exit $err
FLAG_S=$(echo "$CGI" | nameread FLAG_S)
err=$?; [ $err != 0 ] && exit $err
FLAG_A=$(echo "$CGI" | nameread FLAG_A)
err=$?; [ $err != 0 ] && exit $err
SORT=$(echo "$CGI" | nameread SORT)
err=$?; [ $err != 0 ] && exit $err
# ===== 日付の加工(数値以外の文字を全て除く) =====
DAYST=$(echo $DAY_ST | sed 's/[^0-9]//g')
DAYED=$(echo $DAY_ED | sed 's/[^0-9]//g')
# ===== ソート順未指定の場合はdefault値代入 ======
[ "$SORT" == "_" ] && SORT=14 # 14=総累計
# ===== 子シェルを呼んでデータを取り出す =========
$shld/GET_URIAGEDATA $KAISHA_CD \
$HINBAN $DAYST \
$DAYED \
$FLAG_S \
$FLAG_A $SORT |
# 1:品番 2:商品名 3:発売日 4:属性 \
# 5-14:売上 \
dayslash yyyy/mm/dd 3 |
comma 5/14 |
awk '{print $0,NR%2?"eve":"odd"}' > $tmp-table
err=$?; [ $err != 0 ] && exit $err
# 1:品番 2:商品名 3:発売日 4:属性 5-14:売上 15:偶奇
変数を使ったコードは、CGIに渡される値を変数に格納し、コマンド引数という形で別のシェルスクリプトへ処理を振っている。手続き型のプログラミング言語では一般的な方法であり、通常はこの方法で実装するだろう。次にファイルを使う方法を示す。
変数を使ったスクリプト
#!/bin/sh
tmp=/tmp/$$
# ===== オプション取り込み =======================
([ -n ${CONTENT_LENGTH} ] && \
dd bs=${CONTENT_LENGTH} | cgi-name -i_ -d_) > $tmp-name
err=$?; [ $err != 0 ] && exit $err
# ===== 子シェルへ渡すデータの並び順を定義 =======
cat << FIN | self 1/NF | sort > $tmp-name-for-tbl
KAISHA_CD 1
HINBAN 2
DAY_ST 3
DAY_ED 4
FLAG_S 5
FLAG_A 6
SORT 7
FIN
# ===== 子シェルへ渡すデータの順番並べ替え ===== \
cat $tmp-name |
sort |
# 1:ID 2:データ \
join1 key=1 $tmp-name-for-tbl |
# 1:ID 2:並び順 3:データ |
sort -k2 |
self 3 |
tateyoko |
# ===== 一部データの整形(日付加工,ソート順) ==== \
# 1:会社コード 2:品番 3:発売日from \
# 4:発売日to 5:フラグS 6:フラグA \
# 7:ソートキー \
awk '{ gsub(/[^0-9]/, "" ,$3); \
gsub(/[^0-9]/, "" ,$4); \
if ($7=="_") $7=14; \
print; }' |
# ===== 子シェルへデータを(パイプで)渡して実行 = \
$shld/GET_URIAGEDATA |
# 1:品番 2:商品名 3:発売日 4:属性 5-14:売上 \
dayslash yyyy/mm/dd 3 |
comma 5/14 |
awk '{print $0,NR%2?"eve":"odd"}' > $tmp-table
err=$?; [ $err != 0 ] && exit $err
# 1:品番 2:商品名 3:発売日 4:属性 5-14:売上 15:偶奇
ファイルを使ったコードは、CGIに渡される値をファイルに格納し、加工した上でコマンドにパイプで流し込んでいる。手続き型のプログラミング言語では前者のように変数を使う方法が一般的だが、ユニケージ開発手法ではこのようにデータはファイルに格納する。処理の流れは一本だ。
ファイルを使う方法にはいくつかの利点がある。まず、処理の過程がディスク書き込まれるためトレースやデバッグが容易になる。出力されるデータを追うだけで処理を判断できる。また、データの複製がディスクに作成されることで、障害発生時のデータ消失を避けやすくなる。さらにこの方法はビッグデータに対しても綺麗にスケールする。変数に保持する方法では、たとえばデータが100GBや1TBになった場合に対応できない。ファイルに出力する方法では、データは1KBでも1TBでも同じように処理できる。
保持するデータサイズが大きくなると、シェルの変数は性能を発揮することができないという性能上の理由もある。次のシェルスクリプトを実行して動作時間を比較するとよくわかる。
ファイルを使うシェルスクリプト bench_file.sh
#!/bin/sh i=1; : > /tmp/loop.txt while [ $i -le 100000 ]; do echo -n $i >> /tmp/loop.txt i=$((i+1)) done
変数を使うシェルスクリプト bench_var.sh
#! /bin/sh i=1; loop='' while [ $i -le 10000 ]; do loop="$loop$i" i=$((i+1)) done
/usr/bin/timeで実行速度を比較した例を次に示す。
$ /usr/bin/time -lph ./bench_file.sh
real 1.35
user 0.62
sys 0.72
9984 maximum resident set size
136 average shared memory size
12 average unshared data size
128 average unshared stack size
2117 page reclaims
0 page faults
0 swaps
0 block input operations
3 block output operations
0 messages sent
0 messages received
0 signals received
8 voluntary context switches
348 involuntary context switches
$ /usr/bin/time -lph ./bench_var.sh
real 10.47
user 10.44
sys 0.00
9984 maximum resident set size
135 average shared memory size
11 average unshared data size
127 average unshared stack size
2117 page reclaims
0 page faults
0 swaps
0 block input operations
0 block output operations
0 messages sent
0 messages received
0 signals received
2 voluntary context switches
2398 involuntary context switches
$
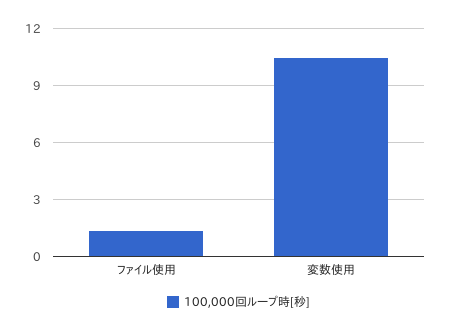
シェル変数はただデータを格納するのではなく、代入する段階でパーサを介してクオート処理、コマンド置換、変数展開、チルダ展開、グロブ展開、文字列処理などさまざまな処理が実施される。このため、処理するデータの長さが増えると、指数関数的に処理に時間がかかるようになる。上記のベンチマークシェルスクリプトの繰り返し回数を100,000回から1,000,000回にしてみるとわかるだろう。bench_file.shは処理時間が10倍に増える程度だが、bench_var.shでは10倍の時間では終わらず、きわめて長い時間がかかるようになる。
※ ユニケージはユニバーサル・シェル・プログラミング研究所の登録商標。
※ usp Tukubaiはユニバーサル・シェル・プログラミング研究所の登録商標。
※ 本ページで公開されているプログラムとそれに付随するデータの著作権およびライセンスは、特に断りがない限りOpen usp Tukubai本体と同じMITライセンスに準拠するものとする。
USP MAGAZINE Vol.5「第三回 ユニケージエンジニアの作法」より加筆修正後転載。
