UECジャーナル
開眼☆シェルスクリプト【13】メールファイルを操作する ―grepでリストを作って一気に処理
はじめに
第12回ではMaildirにたまったメールを日別にディレクトリに整理するという処理を扱った。次のように、ホームディレクトリ以下のMAILというディレクトリに日別にディレクトリを作り、各ディレクトリにメールファイルを分類配置した。また、メールをUTF-8に変換したものも作り、ディレクトリ<日付>.utf8としてデプロイした。
$ ls ← ~/MAIL/の下には日付のディレクトリ 20120610 20120610.utf8 20120611 20120611.utf8 ... $ ls 20120610/ | head -n 3 ← 日付のディレクトリには、それぞれのメールが置かれる 1339304183.Vfc03I46017dM943925.abc 1339305265.Vfc03I46062cM458553.abc 1339306807.Vfc03I4607c6M993984.abc $ ls 20120610.utf8/ | head -n 3 ← <日付>.utf8には、UTF-8化した同名のファイルがある 1339304183.Vfc03I46017dM943925.abc 1339305265.Vfc03I46062cM458553.abc 1339306807.Vfc03I4607c6M993984.abc $
今回は、条件抽出してメールを振り分ける方法や添付ファイルを抜き出す方法を扱う。
メールの振り分け
Logwatchからのメールを抽出し特定のディレクトリに置くという処理をする。Logwatchから送られてくるメールは次のような書き出しではじまる。
################### Logwatch 7.3 (03/24/06) ####################
Processing Initiated: Sun Oct 14 04:00:02 2012
メールを振り分けるにはFrom: logwatch@...の行をgrep(1)で抽出し、grep(1)の出力するファイル名を使ってファイルをどこかにコピーすればよい。たとえば、ホスト名をオプションに指定したら、LOGWATCH_<ホスト名>というディレクトリに当該ファイルをコピーする次のシェルスクリプトLOGWATCHを作成する。
#!/bin/sh -vx
#
# LOGWATCH: 指定したホストのlogwatchメールを収集
# usage: ./LOGWATCH <hostname>
#
# written by R. Ueda (r-ueda@usp-lab.com)
[ "$1" = "" ] && exit 1
server="$1"
dir=/home/ueda/MAIL
dest="$dir/LOGWATCH_$server"
cd "$dir" || exit 1
mkdir -p "$dest" || exit 1
echo ????????.utf8/* |
xargs grep -F "From: logwatch@$server" |
awk -F: '{print $1,substr($1,1,8)}' |
#1:ファイル名 2:日付
awk -v d="$dest" '{print $1,d "/" $2}' |
#1:コピー元 2:コピー先
xargs -n 2 cp
Subjectを調べて、第1引数で指定したホストのLogwatchなら、ディレクトリLOGWATCH_<ホスト名>にファイルをコピーする。Logwatchのメールは1日1通送られてくるので、コピーしたファイル名を日付にする。
grep(1)のオプション-Fは正規表現を使わない指定。メールアドレスにドットが入っていてそのままgrepすると「任意の一字」を示す正規表現として扱われるので、-Fを指定してこれを避けている。fgrep(1)コマンドを使っても同様の処理を実施できる。
&&は左側のコマンドが成功(終了ステータスが0)だったら右側のコマンドを実行するという指定。||はこの逆。mkdir(1)の-pオプションは、すでにディレクトリがあってもエラーにならないようにする指定。一方で、パーミッションなどの理由でディレクトリが作れないときはエラーになる。
最後のawk(1)を通った後のデータは次のようになる。これをxargs(1)で処理してコピーを実施している。
20120611.utf8/1339354818.xyz.abc /home/ueda/MAIL/LOGWATCH_abc.usptomonokai.jp/20120611 20120612.utf8/1339441214.xyz.abc /home/ueda/MAIL/LOGWATCH_abc.usptomonokai.jp/20120612
実行すると次のようになる。
$ ./LOGWATCH abc.usptomonokai.jp 2> /dev/null $ ls LOGWATCH_abc.usptomonokai.jp | head -n 3 20120611 20120612 20120613 $ grep "^From:" ./LOGWATCH_abc.usptomonokai.jp/* | head -n 2 ./LOGWATCH_abc.usptomonokai.jp/20120611:From: logwatch@abc.usptomonokai.jp ./LOGWATCH_abc.usptomonokai.jp/20120612:From: logwatch@abc.usptomonokai.jp $
複数のサーバからLogwatchのメールを受け取っている場合、ホストのリストを作ってシェルスクリプトLOGWATCHを繰り返し実行すれば、Logwatchのメールを振り分けることができる。
添付ファイルを抽出する
次にメールから添付ファイルを抽出する。準備したサンプルメールには画像ファイルが2つ添付(イラストと大きなデジカメ写真)されているものとする。
2つの添付ファイルを含んだメールのサンプル
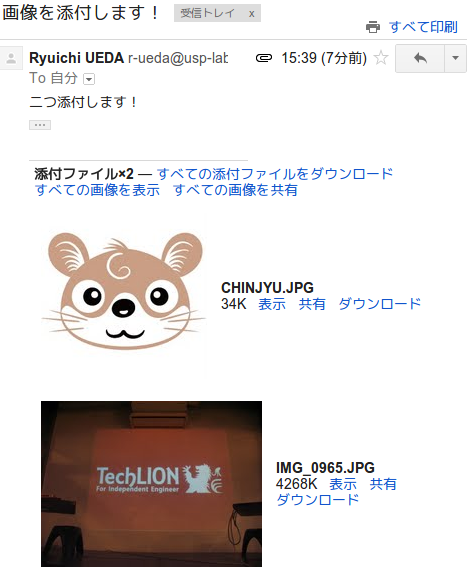
添付ファイルは次のようなテキストファイルとしてメールに書き込まれている。
$ less ./20121016/1350369599.xyz.abc (ヘッダ) Content-Type: multipart/mixed; boundary=047d7b621ee6cf83c604cc276bb3 --047d7b621ee6cf83c604cc276bb3 (メール本文) --047d7b621ee6cf83c604cc276bb3 (添付ファイルをエンコードした文字の羅列) --047d7b621ee6cf83c604cc276bb3 (添付ファイルをエンコードした文字の羅列) --047d7b621ee6cf83c604cc276bb3-- $ wc -l ./20121016/1350369599.xyz.abc 77342 ./20121016/1350369599.xyz.abc $
メールは「MIMEマルチパート」と呼ばれる形式で書き込まれている。MIMEマルチパートにはいくつか種類があるが、1個以上の添付ファイルが含まれたテキスト形式のメールは、multipart/mixedという種類になり、今回はこの形式のメールを処理する。
添付ファイルをメールから抽出するには、boundaryで指定された文字列(境界文字列)で挟まれた領域から中身を抽出する。次のサンプルはCHINJYU.JPGという画像ファイルがどのような形式でメールに保持されているかを示している。
--047d7b621ee6cf83c604cc276bb3 Content-Type: image/jpeg; name="CHINJYU.JPG" Content-Disposition: attachment; filename="CHINJYU.JPG" Content-Transfer-Encoding: base64 X-Attachment-Id: f_h8cn3pxc0 /9j/4AAQSkZJRgABAQEASABIAAD//gATQ3JlYXRlZCB3aXRoIEdJTVD/2wBDAAEBAQEBAQEBAQEB AQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQH/2wBD (略) 0000000000000000000000000000000000000000000000000000000000000000000000000000 0000000000000000000000000000001//9k= --047d7b621ee6cf83c604cc276bb3
この部分は空行をはさんで上側にファイルの情報が書かれたヘッダ、下側にエンコードされたファイルの中身がある。Content-Transfer-Encoding: base64は、Base64という方式でデータがエンコードされていることを示している。
データをBase64でエンコードしたりデコードしたりするにはbase64(1)コマンドを使用する。
$ printf 'データテキスト\n' | base64 44OH44O844K/44OG44Kt44K544OICg== $ printf 'データテキスト\n' | base64 | base64 -d データテキスト $
FreeBSDであればbase64(1)コマンドはPorts Collection (converters/base64)からインストールできる。FreeBSDシステムにデフォルトでインストールされているb64encode(1)やb64decode(1)コマンドを使っても同じ処理を実施できる。
次のシェルスクリプトで、/home/ueda/MAIL/FILES/ディレクトリ以下に<メールファイル名>_<添付ファイル名>で添付ファイルを抽出できる。
#!/bin/sh
#
# EXTFILE: メールから添付ファイルを抽出する。
# usage: EXTFILE <電子メールファイル>
# written by R. Ueda (r-ueda@usp-lab.com) Oct. 16, 2012
[ "$1" = "" ] && exit 1
tmp=/home/ueda/tmp/$$
dest=/home/ueda/MAIL/FILES
##############################################
#境界文字列を抽出
grep -i '^Content-Type:' "$1" |
grep "multipart/mixed" |
#最初にあるもの (=ヘッダにあるもの) だけ処理
head -n 1 |
sed 's/..*boundary=//' |
#「"」がくっついている場合があるので、取って変数に入れる
tr -d '"' > $tmp-boundary
##############################################
#境界でファイルを分割
awk -v b="^--$(cat $tmp-boundary)" -v f="$tmp-F" \
'{if($0~b){a++};print > f a}' "$1"
##############################################
#分割したファイルから添付ファイルを作る
grep -i '^content-disposition:' $tmp-F* |
#1:grepの結果から中間ファイル名と添付ファイル名を抜き出す
sed 's/^\([^:][^:]*\):..*filename=\(..*\)/\1 \2/' |
#1:中間ファイル名 2:添付ファイル名
tr -d '"' |
while read a b ; do
#抽出、デコード、出力
sed -n '/^$/,$p' "$a" |
base64 -d > "$dest/$(basename $1)_${b}"
done
#作ったファイルを表示
ls $dest/$(basename $1)_*
rm -f $tmp-*
exit 0
Content-Type: multipart/mixedの行から境界文字列を取り出している。この部分は取り出せればどのように書いてもよいが、このスクリプトでは本文中にContent-Type: multipart/mixed ...と書いてあっても騙されないように一工夫している。
また、Content-Type:の大文字小文字が間違っていてもよいようにgrep(1)には-iオプションをつけている。Content-Typeの大文字小文字が混じって使われているようすは、次のように確認できる(sm2、countはOpen usp Tukubaiのコマンド)。
$ grep -i "^content-type:" ./*.utf8/* |
awk -F: '{print $2}' | count 1 1 | sort | sm2 1 1 2 2
Content-Type 41367
Content-type 75
content-type 9
$
awk(1)でメールファイルを境界で区切っている。awk(1)の-vオプションはシェルの変数をawk(1)の変数に事前に代入するために使っている。ここでは境界の文字列と切り出し先のファイル名の一部を、それぞれbとfという変数に代入している。if構文で指定している$0~bは、変数bを正規表現扱いして、$0(行全体)と比較するという式。変数を右側に持ってくるときは/は不要。
print > f aは、printで行全体を出力し、その出力先をf aにしている。fはファイル名の一部(/tmp/<プロセス番号>-F)、aは境界文字列が見つかると1つずつ増える数字。awk(1)では文字列と数字を並べるとそのまま文字列として連結するので、リダイレクト先は/tmp/<プロセス番号>-F<数字>となる。
grep(1)でContent-Dispositionの行(添付ファイル名が含まれる)を抽出し、データファイルと復元すべきファイル名のリストを作成する。
リスト11: リスト9、27行目のパイプを通る文字列
/home/ueda/tmp/3560-F2:Content-Disposition: attachment; filename="CHINJYU.JPG" /home/ueda/tmp/3560-F3:Content-Disposition: attachment; filename="IMG_0965.JPG"
sed(1)でファイルの中身部分を取り出し、base64(1)で添付ファイルをデコードしている。sed -n '/^$/,$p'は「空行以降を出力」という意味になる。sed -n '<開始行>,<終了行>p'でファイルにおいてある範囲を行単位で出力する処理ができるので、これは丸暗記しておくと役に立つ。行の指定には正規表現や最終行を表す$などの記号が使える。
$ ./EXTFILE ./20121016/1350369599.xyz.abc /home/ueda/MAIL/FILES/1350369599.xyz.abc_CHINJYU.JPG /home/ueda/MAIL/FILES/1350369599.xyz.abc_IMG_0965.JPG $ cmp ./CHINJYU.JPG ./FILES/1350369599.xyz.abc_CHINJYU.JPG $ echo $? 0 $ cmp ./IMG_0965.JPG ./FILES/1350369599.xyz.abc_IMG_0965.JPG $ echo $? 0 $
デコードされたファイルが元のファイルと同じであるかはcmp(1)コマンドなどで比較すればよい。メールファイルから元の添付ファイルが復元されていることがわかる。
終わりに
ファイルを操作するためのリストを作り、最後にまとめて処理を実施した。この方法はさまざまな処理に汎用的に利用できるので覚えておくと便利だ。ファイルを操作する直前まではテキスト処理になるので、whileのなかでcpやmvの前処理をするよりもデバッグが楽になる。また、立ち上がるコマンドの数も減らすことができる。
Software Design 2013年1月号 上田隆一著、「テキストデータならお手のもの 開眼シェルスクリプト 【13】メールファイルを操作する ―grepでリストを作って一気に処理」より加筆修正後転載
