UECジャーナル
開眼☆シェルスクリプト シェルで画像処理―バイナリデータをテキスト化して扱う
画像ファイル(ppm形式)をシェルスクリプトで操作する方法を解説する。画像データは通常はバイナリ形式でファイルに保存されている。しかし、基本的にはピクセル(画素)ごとにR(赤)、G(緑)、B(青)の値を記録したデータがであれば画像としてデータを表現できる。
ppm形式はそうした画像データのの表現形式の1つ。ppm形式はテキスト(アスキーコード)でデータを持つ形式とバイナリで持つ形式がある。ここではテキストの形式について説明する。次のJPEG形式の写真を素材として扱う。
素材写真

画像の変換にはImageMagickというツールを使用する。GUIアプリケーションのバックエンドとして使われていることもあるので、知らないうちに使っている人は多いかもしれない。Ubuntuならsudo apt-get install imagemagickでインストールできる。FreeBSDであれば/usr/ports/graphics/ImageMagickからインストールできる。
ImageMagickにはconvert(1)という画像やサイズなどを変換するコマンドがある。引数の最後に入力ファイル名と出力ファイル名を書いて変換する。
$ convert -compress none noodle.jpg noodle.ppm $ ls -lh noodle.* -rw-rw-r-- 1 ueda ueda 1.8M 12月 13 11:11 noodle.jpg -rw-rw-r-- 1 ueda ueda 83M 12月 13 13:06 noodle.ppm $
生成されたppmファイルをhead(1)で閲覧してみる。次のようにテキストとして読めたらうまく変換できている。
$ head noodle.ppm P3 2448 3264 255 112 14 13 112 14 13 113 15 14 114 16 15 112 14 13 111 13 12 111 13 12 111 13 12 113 15 14 115 17 16 113 15 ... $
ppm形式のデータは上数行のヘッダ部とその下から始まる数字の羅列で構成されている。ヘッダ部は最初の4個の数字で構成されている。上から順に画像の種類(P3:テキストのppm)、幅、高さ、ピクセルの値の最大値を表す。この画像は2448x3264、256階調で、テキスト形式で保存されているという意味になる。また、#記号があると行末までコメント扱いされているので、なにか処理するときはsed 's/#.*$//'などで除去する。
ボディー部には画像の上の段から順番に、左から右に向かってR、G、Bの順にピクセル値が並ぶ。よく見ると数字が3個ごとに似ていることに気づく。改行とスペースが区切り文字になり、改行はどこに入れてもよいことになっている。
ppm形式はテキストファイルだがLinuxやFreeBSDなどのデスクトップ環境であれば、GUI上でファイルをクリックするとJPEGファイルと同様、画像が閲覧できる。
シェルスクリプトで画像処理
ppm形式のように数字が延々と並んでいるのは後処理が大変なので、次の形式のように5列のデータに変換する。
縦の位置 横の位置 Rの値 Gの値 Bの値
変換には次のシェルスクリプトを作成して使用した。ppm形式のデータからコメントを除去したのち、ヘッダ行を除いた一時ファイル$tmp-ppmへデータを出力。座標をつけるときに画像の幅が必要なので、11行目で $tmp-ppm のヘッダから幅を取得している。
$ cat ppm2data
#!/bin/sh
# ppmを座標とピクセル値のレコードに変換
# written by R. Ueda / Dec. 13, 2012
tmp=/tmp/$$
#コメント行の除去
grep -v '^#' < /dev/stdin > $tmp-ppm
#幅 (ヘッダ二行目の最初の数字) を代入
W=$(awk 'NR==2{print $1}' $tmp-ppm)
tail -n +4 $tmp-ppm |
#数字を縦に並べる
tr ' ' '\n' |
#空行が入るので除去
grep -v '^$' |
#3個ごとに数字を1レコードにする
awk '{printf("%d ",$1);if(NR%3==0){print ""}}' |
awk -v w=$W '{n=NR-1;print int(n/w),n%w,$0}' |
#出力: 1.縦の座標 2.横の座標 3-5. R,G,B値
awk '{print sprintf("%04d %04d",$1,$2),$3,$4,$5}'
rm -f $tmp-*
exit 0
$
実行すると次のような変換結果が表示される。
$ cat noodle.ppm | ./ppm2data > noodle.data $ head -n 3 noodle.data 0 0 112 14 13 0 1 112 14 13 0 2 113 15 14 $ tail -n 3 noodle.data 0000 0000 112 14 13 0000 0001 112 14 13 0000 0002 113 15 14 $ ls -lh noodle.data -rw-rw-r-- 1 ueda ueda 158M 12月 14 10:58 noodle.data $
tail -n +4 は「4行目以降を出力」という意味になる。数字にプラスを付けると、その行数以降という意味になる。tr(1)で空白を改行に変換することで数字を全部縦に並べなおしている。先に縦に並べてから、そのあとで3個ずつ横に並べている。縦に並び直した段階で空行ができる可能性があるので、grep(1)で空行を除去している。
awk '{printf("%d ",$1);if(NR%3==0){print ""}}'は読み込んだ数字を横に並べていって、3回に1回改行を入れるという処理だ。print命令は文字列を出力後に改行を入れるので、print ""と空文字を出力すると改行の意味になる。
awk -v w=$W '{n=NR-1;print int(n/w),n%w,$0}'は各ピクセルのRGB値に座標を与えている。AWKではインデックスは1から数える。NR は今扱っているのが何レコード目かという変数で、これも1からスタートする。画像形式としてはインデックスは0から扱った方がセマンティック的に適切なので、ここのAWKで0から行数をカウントするnという変数を作り、そこから、各ピクセルが上から何行目、左から何列目に位置するかを計算している。
画像を切り出す
ここからはnoodle.dataを使って画像を編集する。最初は画像の一部分を切り出す操作をする。画像の上から約1000ピクセル、下から300ピクセル分を削る処理を実行すると次のようになる。
$ awk '$1>"1000" && $1<"2764"' noodle.data > tmp
$ H=$(awk '{print $1}' tmp | uniq | wc -l)
$ W=$(awk '{print $2}' tmp | tail -n 1 | sed 's/^00*//' | awk '{print $1+1}')
$ awk '{print $3,$4,$5}' tmp > body
$ echo P3 > header
$ echo $W $H >> header
$ echo 255 >> header
$ cat header body > hoge.ppm
$
変換後の素材画像
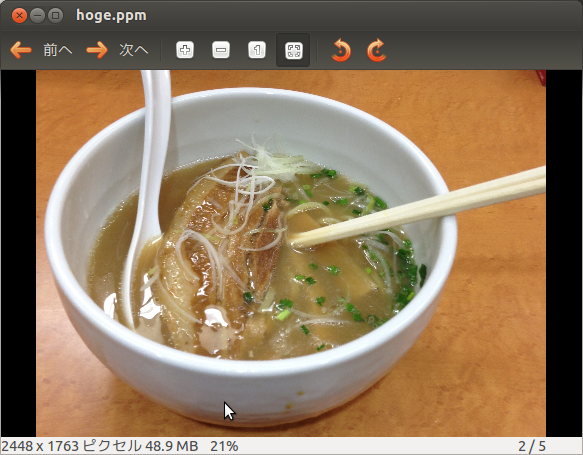
ネガを作る
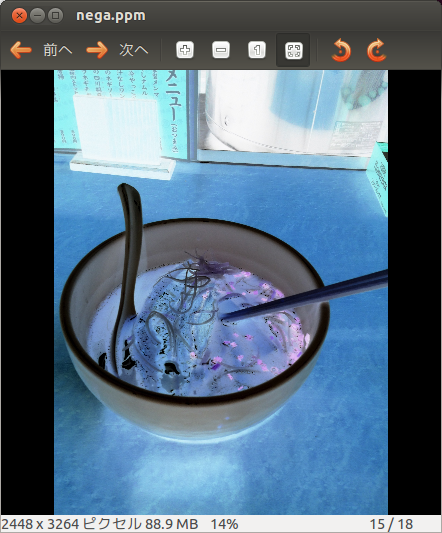
次に、色を反転させてみる。これは簡単で、RGB値それぞれを反転させればよい。
$ cat noodle.data | awk '{print 255-$3,255-$4,255-$5}' > body
$ head -n 3 hoge.ppm | cat - body > nega.ppm
$
次のような画像になる。
変換後の素材画像 その2
画像を合成
次はラーメン画像に別の画像を合成してみる。
合成するための素材画像
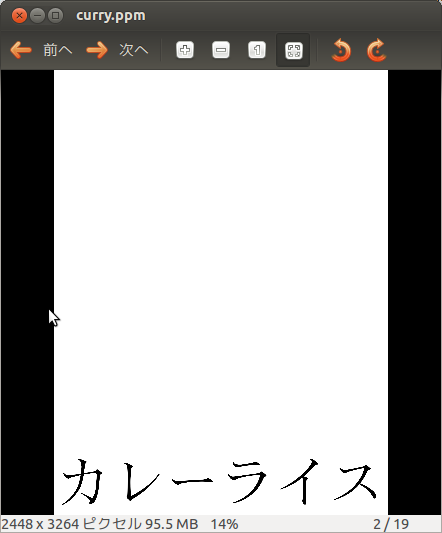
これを次のように処理する。
$ cat curry.ppm | ./ppm2data > curry.data $ loopj num=2 noodle.data curry.data > tmp $ cat tmp | awk '{print $3*$6/255,$4*$7/255,$5*$8/255}' | sed 's/\.[0-9]*//g' > body $ head -n 3 noodle.ppm | cat - body > curry_noodle.ppm $
loopj は Open usp Tukubai のコマンドで、次のような動きをする。2つ以上のファイルの各レコードについて、キーが同じレコードを連結する。num=1 は左から1フィールドをキーするという意味だ。キーはソートされている必要があり、あるファイルにあるキーのレコードがないと、0でパディングされている。
$ cat file1 001 aaa 123 003 bbb 234 $ cat file2 001 AAA 002 BBB 004 CCC $ loopj num=1 file1 file2 001 aaa 123 AAA 002 0 0 BBB 003 bbb 234 0 004 0 0 CCC $
このためloopj num=2 noodle.data curry.data > tmpは画素の位置をキーにしてnoodle.dataとcurry.data を連結しているという意味になる。
$ head -n 3 tmp 0000 0000 112 14 13 255 255 255 0000 0001 112 14 13 255 255 255 0000 0002 113 15 14 255 255 255 $
awk '{print $3*$6/255,$4*$7/255,$5*$8/255}'ではnoodleとcurryのピクセルを比較して、curryの字のない部分(RGBそれぞれ値が255)についてはnoodle の値、字のある部分については画素が黒くなる演算をしている。たとえば$3*$6/255は$6=255なら答えは$3の値になるし、$6=0なら答えは0になる。
合成された画像

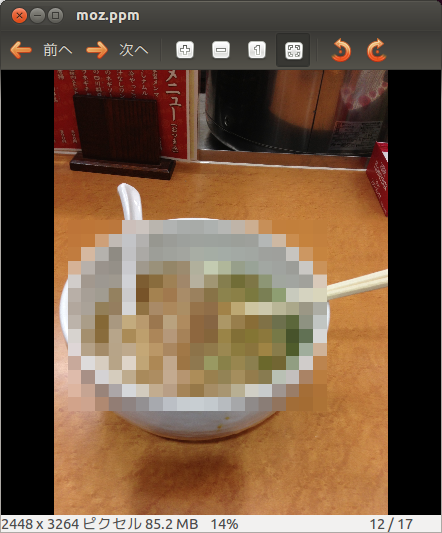
モザイクをかける
最後にモザイクをかける操作をしてみる。まず、素材画像を100ピクセルごとに区切ってブロック化する。次のようにnoodle.dataの座標からグループのコードを作る。tail(1)の出力のように、たとえば(3263,2445)はグループ(32,24)ということを各レコードの後ろに付加しておく。
$ awk '{print $0,substr($1,1,2),substr($2,1,2)}' noodle.data > tran
$ tail -n 3 tran
3263 2445 199 132 90 32 24
3263 2446 198 131 89 32 24
3263 2447 199 132 90 32 24
$
次に、各グループの画素値を平均する。このデータがモザイクのレイヤになる。
$ awk '{print $6,$7,$3,$4,$5}' tran | sort -k1,2 -s | sm2 +count 1 2 3 5 | awk '{print $1,$2,$4/$3,$5/$3,$6/$3}' | sed 's/\.[0-9]*//g' > mean
$
上のコードでは、まずグループを左側に持ってきてキーにして、ソートしOpen usp Tukubaiコマンドのsm2 で足し込んでいる。sm2の後の出力は次のようになる。
$ awk '{print $6,$7,$3,$4,$5}' tran | sort -k1,2 -s | sm2 +count 1 2 3 5 | head -n 3
00 00 10000 1096186 274854 214869
00 01 10000 1049205 268678 207120
00 02 10000 1048624 266316 212040
$
sm2 +count 1 2 3 5 は、1、2列目をキーにして、キーごとに3~5列目を足し込むという意味になる。+countをつけると、足し込むときにキーの数を数えておき、レコードの出力の際にキーの横に数を付加する。なので、この出力の6、7、8列目を3列目で割ると、各グループの平均のRGB値になる。
sort -k1,2 -sの-sだが、これはソートキーが同じレコードの順番を変えない「安定ソート」のオプションだ。この処理では安定ソートは不要だが、 sortコマンドは安定ソートの方が早く終わるので経験的に付けている。なお、-sオプションは標準的な機能ではないものの、現在でも広く使われているオプションとされている。
生成したファイルmeanの一部を次に示す。
$ tail -n 3 mean 32 22 194 132 78 32 23 200 137 86 32 24 200 138 89 $
モザイクのレイヤのRGB値が計算できたら、さきほど作ったtranファイルにmeanファイルを連結する。
$ cjoin1 key=6/7 mean tran | delf 6 7 > tmp $ tail -n 3 tmp 3263 2445 199 132 90 200 138 89 3263 2446 198 131 89 200 138 89 3263 2447 199 132 90 200 138 89 $
cjoin1というOpen usp Tukubaiコマンドを使った。このコマンドはtranの第6、7列目のデータとmeanの左2列を比較してmeanの内容をtranに連結する。join1 というコマンドもあるのだが、こちらはtran側が6、7列目でソートしていないと使えない。マスタ扱いされるmeanの方は、cjoin1でもキーでソートされている必要がある。
delfは指定した列を消すコマンドで、既に不要なグループのキーを消去している。
tmpが作成できたら次のようにコマンドを実行する。画像の範囲指定をして範囲内ならモザイクのRGB値、範囲外なら元の画像のRGB値を出力している。
$ awk '{if($1>=1000&&$1<=2400&&$2>=100&&$2<=2000){print $6,$7,$8}else{print $3,$4,$5}}' tmp > body
$ head -n 3 noodle.ppm | cat - body > moz.ppm
$
合成された画像 その2
終わりに
シェルでバイナリデータを扱うという観点から画像処理を実施した。最初の段階でデータをテキストデータに変換するところがポイントとなる。バイナリデータだから扱いにくいといったものではなく、結局、バイナリ形式とテキスト形式を相互に変換する道具さえあればよいになる。両者にデータとしての本質的な違いはない。
Software Design 2013年3月号 上田隆一著、「テキストデータならお手のもの 開眼シェルスクリプト 【15】シェルで画像処理(1)―バイナリデータをテキスト化して扱う」より加筆修正後転載
