UECジャーナル
開眼☆シェルスクリプト 【8】CPUに効率よく仕事をさせる(1) ― パイプによる処理の並列
はじめに
コマンドに手分けさせて仕事をさせる方法を扱う。2012年現在のノートPCはCPUのコアが2個以上あるものが多いので、これを休ませずに働かせる。
今回扱うのは、最重要並列化テクニックは次のものだ。
「普通にパイプを使う」
先に答えを言ってしまうと、パイプにつなげたコマンドは並列に動作する。それを使おうというのが今回のお題だ。
パイプにつながったコマンドの挙動
標準入力から文字列データを受けて駆動するタイプのコマンドは、パイプやファイルからの入力がないと待ちの状態になる。パイプにつながったコマンドたちは、互いに影響を受けながら待ちの状態とアウトプットしている状態を繰り返す。たとえCPUのコアが1個であっても、細かい時間間隔で各コマンドが入り乱れて動くので、パイプにつながったコマンドは同時に動いているように見える。
ここでコアが2個あったらどうなるか考えてみる。コアが1個でも細かい時間刻みで各コマンドが動いているということは、単純に考えて1個のコアで半分受け持てばよいということになる。問題は、片方のコアから発生する出力をもう一方のコアに持っていく手間が必要になることだが、端末を操作している側の人間は気にしなくてよいほど効率化されている。
パイプは基礎
ここ数年はCPUのマルチコア化によってさまざまな並列処理技術が開発されている。そうしたさまざまな技術と比較して、パイプはきわめて取扱いが簡単だ。パイプはOSの提供する基礎技術であり、簡素にして効率的といえる。
応用技術はOS側が要件を満たしていないと動かない。実際、派手な名前がついているフレームワークやソフトウェアでも、内部はパイプを使ったり、プロセスを操作したりとOSの機能を使っているわけだ。また、どんなプラットフォームでも動くような技術は、さまざまな違いを吸収しなければならない。そのため、OSの違いを吸収するライブラリなどが増えてしまいがちだ。なので、セットアップから使用までにどうしても手間がかかる。
一方OSの各機能は、とにかく単機能でシンプルに使えるように実装されている。パイプなら「|」、ファイル入出力なら「<、>」など、ユーザがよく使うものはシェルから記号1つで呼び出せる。特にUNIX系OSで言えることだが、OSの開発者自身がOSのヘビーユーザなので、簡単ぶりが徹底されている。また、OSの評価は各機能のパフォーマンスと使いやすさで決まるので、開発や改良にかなり力が入る部分でもある。パイプに関係する処理も、OSのメジャーバージョンアップの際にパフォーマンスが向上することがある。
あまり、あれがよいこれがよいと比較するつもりはないのだが、パイプについてはシェルで簡単に使えるよう、お膳立てされているので積極的に使うべきだと思う。少なくともOSの機能としては基礎の基礎なので、これを知らずに他の応用技術をあれこれ議論するのはよろしくないだろう。
故事
パイプはDouglas McIlroy氏によって発明された。UNIXに実装される前後の経緯やMcIlroy氏とThompson氏ら同僚の様子についてはOn the Early History and Impact of Unix - Tools to Build the Tools for a New Milleniumにおもしろい記述がある。この文献によると、パイプの導入はUNIXの開発では少し後回しになっていたものの、実装されると既存のUNIXコマンドの書き直しやgrep(1)コマンドの誕生を誘発するなど、黎明期のUNIXに強烈なインパクトを与えたようである。
お題:パイプを使ってCPUを使い切る
Lenovo ThinkPad SL510でベンチマークを実施する。2011年現在5万円ほどで販売されていたノートPCだ。コンシューマ向けプロダクトとして廉価なモデルといえる。
リスト1: ベンチマークマシーン (Lenovo ThinkPad SL510)
$ cat /proc/cpuinfo | grep "model name" model name : Celeron(R) Dual-Core CPU T3100 @ 1.90GHz model name : Celeron(R) Dual-Core CPU T3100 @ 1.90GHz $ uname -a Linux uedaubuntu 3.2.0-24-generic #38-Ubuntu SMP Tue May 1 16:18:50 UTC 2012 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a 2>/dev/null | grep Description Description: Ubuntu 12.04 LTS $
ベンチマークにはApache HTTPd Serverのアクセスログを使用する。
$ ls access_log-20120213.gz ... access_log-20120521.gz access_log-20120522.gz $ zcat access_log-20120522.gz | head -n 1 219.94.249.xxx - - [21/May/2012:03:31:13 +0900] "GET /TOMONOKAI... (略) $ zcat *.gz | wc -l 424787 $ cat *.gz | wc -m 3570682 $ zcat *.gz | wc -m 96886530 $
50万行程では短すぎるので、ベンチマーク用に同じログを何回もくっつけて1GBのベンチマーク用ファイルを作る。
$ zcat *.gz > log
$ cat log{,,,,,,,,,,} > log1G
$ ls -lh log1G
-rw-rw-r-- 1 ueda ueda 1017M 5月 22 14:38 log1G
$
処理時間の測り方
コマンドの処理時間は、time(1)コマンドで測る。たとえば、ファイルを全部解凍してファイルに出力する時間を測ると次のようになる。
$ time zcat *.gz > hoge real 0m0.957s user 0m0.588s sys 0m0.156s $
realが実際 (我々の世界) でかかった時間、userとsysはそれぞれ、CPU時間 (CPUが働いた時間) のうち、ユーザモードだった (カーネル以外のプログラムが動いた) 時間、カーネルモードだった時間だ。普通はIOや切り替えコストなどの理由で、CPU時間よりもrealの時間が長くなる。
計測の際、ハードディスクへの出力の遅延を気にしたくない場合は、次のように /dev/null というところに出力をリダイレクトする。この例の場合には、ほぼ real = user + sys になっている。
$ time zcat *.gz > /dev/null real 0m0.563s user 0m0.560s sys 0m0.004s $
/dev/nullはなんでも吸い込んで消してしまう特殊なファイルだ。コマンドの出力をここにリダイレクトしておくと、消えてなくなる。実際のIOは発生しないため処理が高速に完了するという特徴がある。/dev/nullは日本語では「デブルヌ」と呼ばれることが多いように思う。
パイプでつながっていないコマンドの処理時間を端末で計測したいときには、次のようにコマンドをセミコロンで区切って括弧で囲む方法がある。あるいはシェルスクリプトにして計測してもよいだろう。
$ time ( sleep 1 ; sleep 2 ) real 0m3.003s user 0m0.000s sys 0m0.000s $
パイプラインの並列処理
次の処理はlog1Gファイルをsed(1)コマンドで読み込み、aをすべてbに置換している。2つ目の処理では、さらにパイプの後ろにsed(1)コマンドをつなげ、bをaに置換している。
リスト2: パイプを使う
$ time sed 's/a/b/g' < log1G > /dev/null real 0m12.439s user 0m10.505s sys 0m0.876s $ time sed 's/a/b/g' < log1G | sed 's/b/a/g' > /dev/null real 0m14.938s user 0m24.338s sys 0m1.900s $
2つ目の処理の方が2.5[s]遅いが、注目すべきはuserの値がrealの値を上回っていることである。実際にかかった時間よりもCPU時間が長いということは、平均してコアが1個以上使われているということになり、並列化されているということになる。
リスト3は、処理中にtop(1)コマンドを実行したものだ。sed(1)のCPU使用率が92%と82%で、足すとsed(1)だけで1.7個コアを使用していることになる。
リスト3: sedをパイプでつないだ処理中のtop(1)の出力
$ top -n 1 -b | sed -n '/PID/,$p' | head -n 5 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 13108 ueda 20 0 16644 832 704 R 92 0.0 0:04.37 sed 13107 ueda 20 0 16644 828 704 R 82 0.0 0:03.82 sed 1089 root 20 0 198m 25m 6480 S 2 1.4 5:40.79 Xorg 2023 ueda 20 0 1261m 64m 10m S 2 3.4 4:06.40 compiz $
パイプを使わずに同様の処理をすると次のようになる。
$ sed 's/a/b/g' < log1G > hoge ; sed 's/b/a/g' < hoge > /dev/null ; rm hoge real 0m43.570s user 0m23.893s sys 0m4.480s $
パイプを使ったほうがスマートに記述できることがわかる。
もっとつなぐとどうなるか?
パイプで並列処理ができるとなると、どこまでパイプでつないでよいのかという疑問が生じる。並列度が論理コア数を超えた場合、コンテキストスイッチやハードウェアのIO回りの処理が原因で性能が劣化すると考えられる。
ベンチマークを実施してみよう。sed(1)で1GBのファイルのアルファベットを一文字ずつ変換する。下のコマンドラインのように、aをb、cをd・・・と変換するsed(1)コマンドをパイプで数珠つなぎにして処理時間を計測する。sed(1)の数は1~13まで変化させる。処理の総量はsed(1)の数に比例して大きくなる。
$ time sed 's/a/b/g' < log1G | sed 's/c/d/g' > /dev/null # 2連続の場合 $ time sed 's/a/b/g' < log1G | sed 's/c/d/g' | (略) | sed 's/w/x/g' | sed 's/y/z/g' > /dev/null # 13連続の場合
ベンチマーク結果をグラフにまとめると次のようになる。
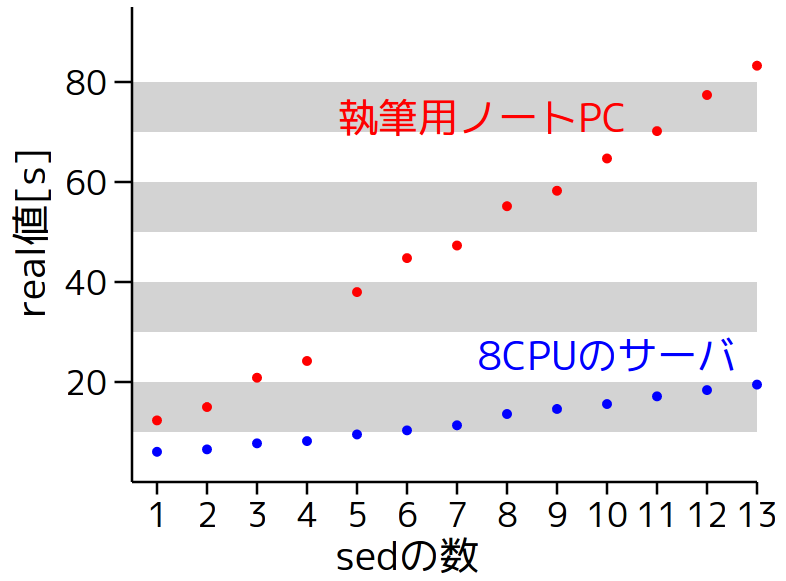
図1: 処理時間
ほぼ線形で時間が増えており、処理量に比例して時間が増えているように見える。この図ではあまり傾向がつかめないので、計測時間をsed(1)の数で割ってみたものを図2に示す。この図は、同じ処理量で計算能力を比較したものになる。
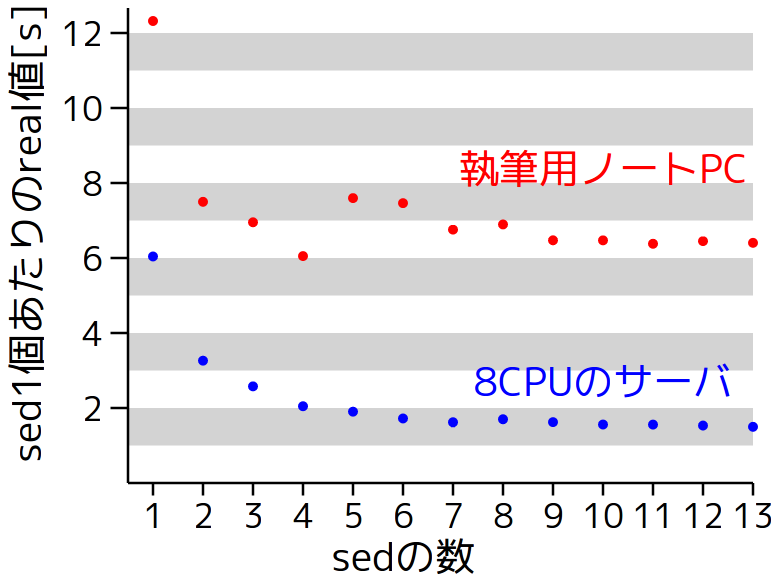
図2: sed一個あたりの処理時間
sed(1)が1個のときよりも2個のときの方が、時間あたりにたくさんの処理をこなせていることがわかる。8コアのサーバの場合は、7個あたりまで時間が短くなっている。
今回のケースではパイプでつながったsed(1)の数がコアの数を上回っても、この範囲では性能が落ちないことも分かる。
負荷にばらつきがある場合
さきほどのベンチマークでは、それぞれのsed(1)の負荷にあまり違いがないようにしていたが、そうでないときはどうなるだろうか。
たとえば、同じ置換のコマンドであっても、tr(1)コマンドはsed(1)に比べてかなり高速だ。そのため、sed(1)とtr(1)をパイプでつなげると、どの順序で組み合わせても、リスト4の例のようにtr(1)が遊んでしまう。
リスト4: sed(1)とtr(1)をつなげるとtr(1)が遊ぶ
$ sed 's/a/b/g' < log1G | tr 'c' 'd' > /dev/null ↓ $ top %CPU %MEM TIME+ COMMAND 96 0.0 0:07.82 sed 23 0.0 0:01.89 tr 10 14.4 12:03.30 chromium-browse 2 0.0 0:03.36 kswapd0 $
組み合わせを逆にしても同じ
$ tr 'c' 'd' < log1G | sed 's/a/b/g' > /dev/null ↓ $ top %CPU %MEM TIME+ COMMAND 86 0.0 0:03.25 sed 29 0.0 0:01.04 tr 2 0.0 0:04.23 kswapd0 2 1.1 8:51.42 Xorg $
grep(1)で検索した結果を後続のコマンドで処理するというのはよくあることだが、このときは後のコマンドで扱うデータ量が少ないので、これも負荷に違いが出る。次のワンライナーを見てみよう。grep(1)とawk(1)で扱うレコード数が数倍違うので、負荷もそれくらいの違いが出る。
$ grep Chrome log1G | awk '{print $1,$4,$5}'
114.182.aaa.xxx [05/Feb/2012:16:24:46 +0900]
114.182.aaa.xxx [05/Feb/2012:16:24:46 +0900]
・・・
$
こうしたケースでは、一番負荷の高いコマンドの処理時間以上に処理が早く終わることはない。これはパイプの並列化の限界で、もしもっと速い処理が必要ならば、別の方法をとる必要がある。
ただし、負荷の高いコマンドを待っている間に他のコマンドとコアを効率的に使うことは可能だ。次のように、sed(1)がほぼ1個分のコアを占領していても、他のコマンドの負荷が軽ければそちらは自動的に処理が分散される。
$ time sed 's/a/b/g' < log1G | tr 'c' 'd' | tr 'e' 'f' | tr 'g' 'h' | tr 'i' 'j' | tr 'k' 'l' > /dev/null ↓ $ top %CPU %MEM TIME+ COMMAND 82 0.0 0:04.95 sed 19 0.0 0:01.28 tr 16 0.0 0:00.92 tr 14 0.0 0:00.90 tr 14 0.0 0:00.86 tr 14 0.0 0:00.90 tr 14 0.0 0:00.82 tr $
冒頭で、「たとえコアが1個であっても、細かい時間間隔で各コマンドが入り乱れて動く」と言ったように、コマンドを2つつなげたらそれぞれがコアを一個ずつ占領するわけではない。たとえばコアが2つの今回のベンチマークノートPCで、パイプでつなげたコマンドが3個以上あっても、カーネルのスケジューラはコアが遊ばないように処理を分散する。パイプが何段必要かは処理によって違うので、無理にパイプをつなげて処理することはないが、ちょっと頭の隅に置いておくとよいだろう。
もう1つ、特にawk(1)やsed(1)を使って重たい処理をする場合に実践的な方法だが、処理を分割すると早くなるという例を下に示す。
$ head -2 log1G 114.182.aaa.xxx - - [05/Feb/2012:16:24:46 +0900] "GET (略) 114.182.aaa.xxx - - [ 05 Feb 2012 162446 +0900] "GET (略) $ time sed -e 's@\(..\)/\(...\)/\(....\)@ \1 \2 \3@' -e 's/:\(..\):\(..\):\(..\)/ \1\2\3/' < log1G > /dev/null real 0m29.488s user 0m28.994s sys 0m0.492s $ time sed 's@\(..\)/\(...\)/\(....\)@ \1 \2 \3@' < log1G | sed 's/:\(..\):\(..\):\(..\)/ \1\2\3/' > /dev/null real 0m22.807s user 0m32.382s sys 0m2.064s $
CPUバウンダリな処理ではこのように処理を複数のコアへ分割した方が処理が高速に終わる場合が多い。シェルスクリプトの場合には、分けて書いた方が読みやすいということもある。
8コアのサーバでさらに分散処理させると次のようになる。
$ time sed -e 's@\(..\)/\(...\)/\(....\)@ \1 \2 \3@' -e 's/:\(..\):\(..\):\(..\)/ \1\2\3/' < log1G > /dev/null real 0m17.551s user 0m17.209s sys 0m0.303s $ time sed 's/\[/& /' < log1G | sed 's@/@ @' | sed 's@/@ @' | sed 's/:/ /' | sed 's/://' | sed 's/://' > /dev/null real 0m5.773s user 0m17.252s sys 0m10.959s $
データをブロックするコマンドがある場合
sort(1)のようにデータをすべて処理した後でなければ出力をはじめないコマンドもある。次のケースでは、sort(1)コマンドが終わるまでawk(1)以後の処理は開始されない。
$ time zcat *.gz | sort | awk '{print $1}' | uniq -c
無理に回避する必要はないが、早く処理を終わらせるテクニックはある。今回のケースでは単純にgrep(1)とawk(1)の順序を変えるだけで処理時間が違ってくる。
$ time zcat *.gz | sort | awk '{print $1}' | uniq -c | head -n 3
10 1.112.aaa.xxx
37 1.112.bbb.yyy
10 1.112.ccc.zzz
real 0m5.561s
user 0m4.544s
sys 0m0.384s
$ time zcat *.gz | awk '{print $1}' | sort | uniq -c | head -n 3
10 1.112.aaa.xxx
37 1.112.bbb.yyy
10 1.112.ccc.zzz
real 0m1.991s
user 0m2.452s
sys 0m0.144s
$
このケースではsort(1)に入れるデータ量を減らすということが効率の改善になっている。さらに、後者の並び次の2つのグループが同時に実行されることが分かっていることも大事だ。
zcat(1)、awk(1)、sort(1)のデータ読み込みsort(1)の出力、uniq(1)、head(1)
後者のreal値とuser値が逆転しているように、並列化の効果はsort(1)が間にあっても出ている。
おわりに
コマンドをパイプで接続して処理するというのは、大量のデータを処理するシェルスクリプトを書く際には必須の知識だ。コアが2個でもコマンドを何個もつなぐことでパフォーマンスが向上することはお見せできたと思う。コアが多いと、ベンチマークで出てきたサーバ機のように効果はより明確になる。
また、McIlroyについて触れたが、パイプはUNIXの特性に大きな影響を与えている。パイプの発明が我々に大きな恩恵を与えていることは疑いのないことだ。
Software Design 2012年8月号 上田隆一著、「テキストデータならお手のもの 開眼シェルスクリプト 【8】CPUに効率よく仕事をさせる ― パイプによる処理の並列化」より加筆修正後転載
